NFVbench supports the following main measurement capabilities:
NDR is the highest throughput achieved without dropping packets. PDR is the highest throughput achieved without dropping more than a pre-set limit (called PDR threshold or allowance, expressed in %).
Results of each run include the following data:
NFVbench can stage OpenStack resources to build 1 or more service chains using direct OpenStack APIs. Each service chain is composed of:
OpenStack resources are staged before traffic is measured using OpenStack APIs (Nova and Neutron) then disposed after completion of measurements.
The loopback VM flavor to use can be configured in the NFVbench configuration file.
Note that NFVbench does not use OpenStack Heat nor any higher level service (VNFM or NFVO) to create the service chains because its main purpose is to measure the performance of the NFVi infrastructure which is mainly focused on L2 forwarding performance.
NFVbench supports settings that involve externally staged packet paths with or without OpenStack:
NFVbench supports benchmarking of pure L2 loopbacks (see “–l2-loopback vlan” option)
In this mode, NFVbench will take a vlan ID and send packets from each port to the other port (dest MAC set to the other port MAC) using the same VLAN ID on both ports. This can be useful for example to verify that the connectivity to the switch is working properly.
NFVbench currently integrates with the open source TRex traffic generator:
Packet paths describe where packets are flowing in the NFVi platform. The most commonly used paths are identified by 3 or 4 letter abbreviations. A packet path can generally describe the flow of packets associated to one or more service chains, with each service chain composed of 1 or more VNFs.
The following packet paths are currently supported by NFVbench:
The traffic is made of 1 or more flows of L3 frames (UDP packets) with different payload sizes. Each flow is identified by a unique source and destination MAC/IP tuple.
NFVbench provides a loopback VM image that runs CentOS with 2 pre-installed forwarders:
Frames are just forwarded from one interface to the other. In the case of testpmd, the source and destination MAC are rewritten, which corresponds to the mac forwarding mode (–forward-mode=mac). In the case of VPP, VPP will act as a real L3 router, and the packets are routed from one port to the other using static routes.
Which forwarder and what Nova flavor to use can be selected in the NFVbench configuration. Be default the DPDK testpmd forwarder is used with 2 vCPU per VM. The configuration of these forwarders (such as MAC rewrite configuration or static route configuration) is managed by NFVbench.
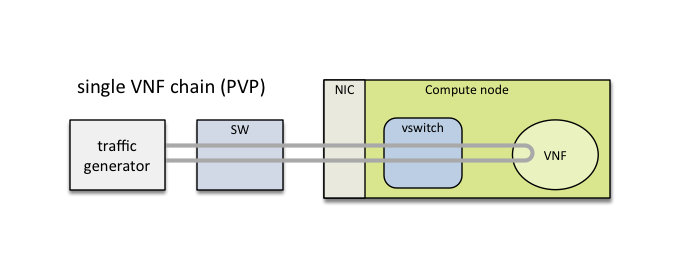
This packet path represents a single service chain with 1 loopback VNF and 2 Neutron networks:
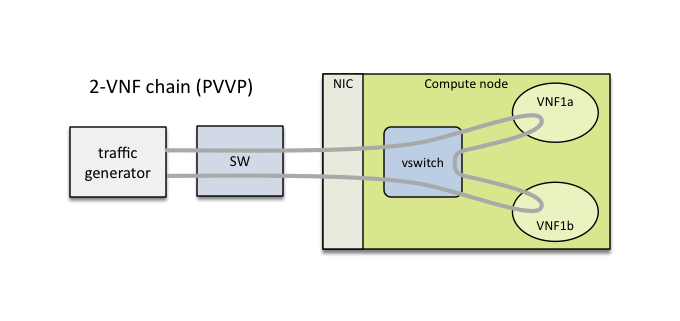
This packet path represents a single service chain with 2 loopback VNFs in sequence and 3 Neutron networks. The 2 VNFs can run on the same compute node (PVVP intra-node):
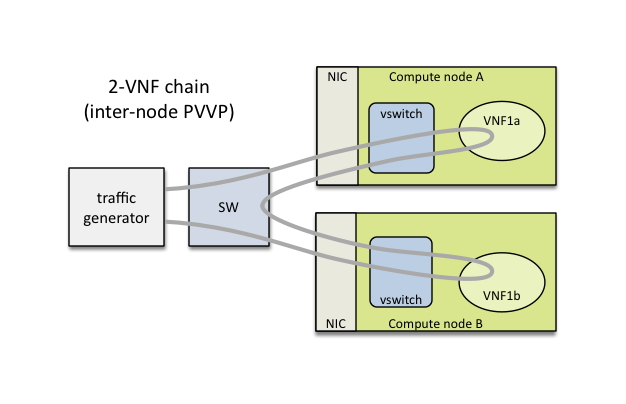
or on different compute nodes (PVVP inter-node) based on a configuration option:
Multiple service chains can be setup by NFVbench without any limit on the concurrency (other than limits imposed by available resources on compute nodes). In the case of multiple service chains, NFVbench will instruct the traffic generator to use multiple L3 packet streams (frames directed to each path will have a unique destination MAC address).
Example of multi-chaining with 2 concurrent PVP service chains:
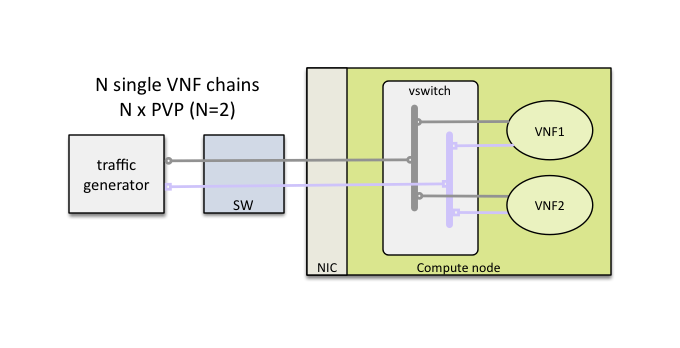
This innovative feature will allow to measure easily the performance of a fully loaded compute node running multiple service chains.
Multi-chaining is currently limited to 1 compute node (PVP or PVVP intra-node) or 2 compute nodes (for PVVP inter-node). The 2 edge interfaces for all service chains will share the same 2 networks. The total traffic will be split equally across all chains.
By default, service chains will be based on virtual switch interfaces.
NFVbench provides an option to select SR-IOV based virtual interfaces instead (thus bypassing any virtual switch) for those OpenStack system that include and support SR-IOV capable NICs on compute nodes.
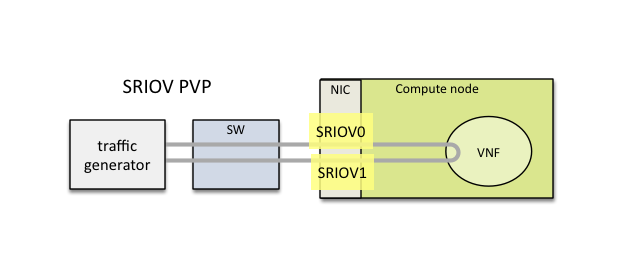
The PVP packet path will bypass the virtual switch completely when the SR-IOV option is selected:
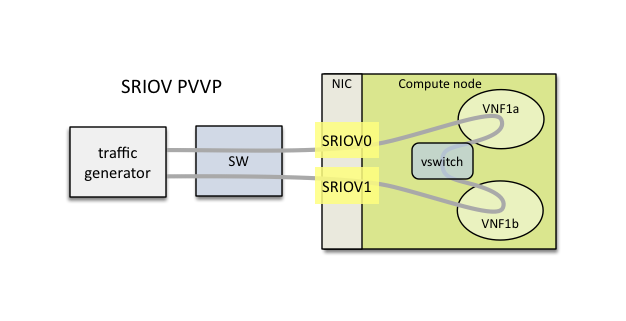
The PVVP packet path will use SR-IOV for the left and right networks and the virtual switch for the middle network by default:
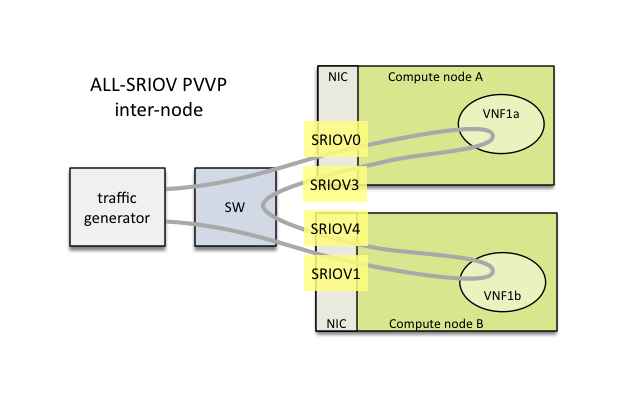
Or in the case of inter-node:
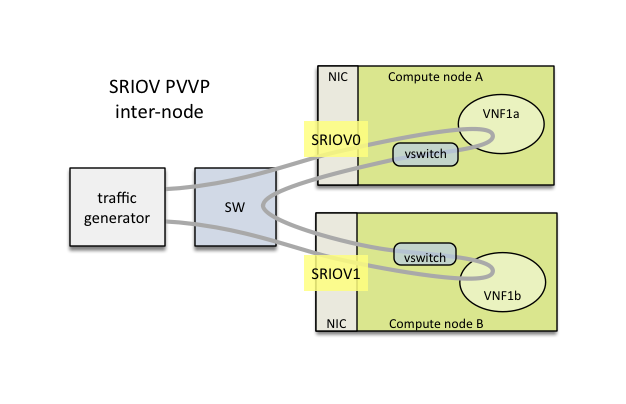
This packet path is a good way to approximate VM to VM (V2V) performance (middle network) given the high efficiency of the left and right networks. The V2V throughput will likely be very close to the PVVP throughput while its latency will be very close to the difference between the SR-IOV PVVP latency and the SR-IOV PVP latency.
It is possible to also force the middle network to use SR-IOV (in this version, the middle network is limited to use the same SR-IOV phys net):
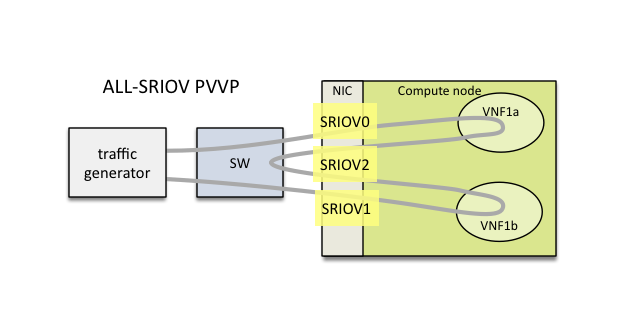
The chain can also span across 2 nodes with the use of 2 SR-IOV ports in each node:
P2P (Physical interface to Physical interface - no VM) can be supported using the external chain/L2 forwarding mode.
V2V (VM to VM) is not supported but PVVP provides a more complete (and more realistic) alternative.
NFVbench only supports VLAN with OpenStack. NFVbench does not support VxLAN overlays.